最大内積探索(MIPS)のライブラリを公開しました
読了時間8分
エンジニアの谷田です。 最大内積探索問題(Maximum Inner Product Search, 以下MIPS)ってご存知でしょうか?データベースに登録された多くのアイテムのベクトルのうち、クエリのベクトルとの内積を最大化するアイテムを探す問題です。行列分解を用いてユーザにアイテムをレコメンドするときなど、この探索が問題になってくることがあります。 MI […]
読了時間8分
エンジニアの谷田です。 最大内積探索問題(Maximum Inner Product Search, 以下MIPS)ってご存知でしょうか?データベースに登録された多くのアイテムのベクトルのうち、クエリのベクトルとの内積を最大化するアイテムを探す問題です。行列分解を用いてユーザにアイテムをレコメンドするときなど、この探索が問題になってくることがあります。 MI […]
読了時間10分
こんにちは.エンジニアをしている田中です. 近年の多くの推薦システムでは,機械学習手法を用いて,ユーザの行動履歴から推薦モデルを構築するようになってきています.これにより,単にデータを集計して人気のアイテムを出すようなアプローチと比べて,よりユーザの趣向に合ったアイテムを推薦することが可能になります.ここでは,そのような推薦モデルの構築(学習)方法について, […]
読了時間5分
こんにちは。白ヤギコーポレーション、エンジニアの乗松です。 この度、Go言語で実装されたダブル配列ライブラリを公開しましたのでお知らせします。 https://github.com/shiroyagicorp/double_array 何に使うもの? ある文字列があらかじめ定義した集合に含まれているかどうか判定するときに使います。 ダブル配列って何? Tri […]
読了時間10分
白ヤギリードアーキテクトの伊藤です。 3/2〜4にtry! Swift Tokyo 2017が開催され、そして今回、Apple以外のプラットフォームでのSwift活用法についてお話しました。 前回サーバーサイドSwiftでの記事を書いてから、しばらくぶりになりましたが、近況を簡単に報告することができました。 Swiftのオープンソース化から1年半ほどたちまし […]
読了時間10分
白ヤギの開発者の森本です。 今週の中日 (2016-09-20から09-24) から PyCon JP 2016 が開催されました。白ヤギコーポレーションは例年スポンサーをしていますが、「シルバースポンサーではうちの会社が目立たないだろう」的なノリで今年は初めてゴールドスポンサーとして参加しました。普段なら私は個人としてチケットを購入してカンファレンスに参加 […]
読了時間10分
白ヤギの開発者の森本です。 白ヤギではニュース記事のキュレーションをする カメリオ API というサービスを開発していますが、検索バックエンドとして Elasticsearch を使っています。 カメリオ API は約1年3ヶ月前に開発を始めたのですが、当時は 1.7 系を使っていました。昨年の夏から秋ごろにかけて 2.0.0 のベータ版がリリースされ、20 […]
読了時間5分
先日 Go で API サーバーを開発してきて1年が過ぎました という記事を書きました。昨日、Go 1.7 がリリース されなかった (もとは8/8がリリース予定だったのが8/15に延期された) わけですが、そのリリースパーティが行われました。先日のブログに関して話してほしいという依頼を頂いたので発表してきました。運営の方々、発表の場を頂いてありがとうござい […]
読了時間15分
白ヤギの開発者の森本です。 白ヤギでは Go 言語でニュース記事のキュレーションをする カメリオ API というサービスを開発しています。約1年2ヶ月前、Go を使って開発し始めたときに当時調べた内容を整理して以下の記事を書きました。 Go言語で API サーバーを開発する 1年以上に渡り開発を継続してきて変わったこと、変わってないことなどをざっくばらんにま […]
読了時間10分
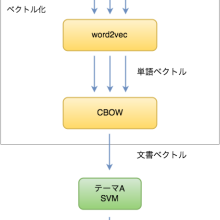
はじめまして。白ヤギコーポレーションでエンジニアをしている谷田です。 カメリオでは、テーマに合ったニュース記事を提供するために、機械学習を応用した新しいアプローチを最近こっそり導入しました。この記事では、カメリオがどのようにニュース記事がテーマに合っていると判断しているのか、そのアルゴリズムの概要を解説してみたいと思います。 カメリオでは新しく入ってきたニュ […]
読了時間15分
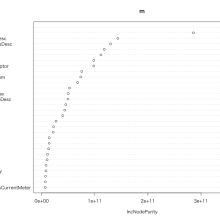
白ヤギコーポレーションのデータ分析担当 堅田です。 今回は、時間がない中でデータをさくっと分析したいという人向けに、RのrandomForestパッケージを使った分析方法を紹介したいと思います。 データの前処理 まずデータの前処理では、難なくRのrandomForestに突っ込むための加工を施します。主なステップは以下の4つです。 1. データのサンプリング […]