こんにちは、シバタアキラ(@punkphysicist)です。
明日NikkeiBPさんから発売予定の「図解と数字で説得する! データプレゼンテーションの教科書」の 記事のために、自然言語処理を使った分析をさせていただきましたのでご紹介させていただきます。こんなビジュアルのかっこいい分析です。

今回ご協力させていただいた本にご興味をお持ちの方は下記からお探し頂けます!下記日経BPさんのご紹介
得られた答えや発見を図解やビジュアルの形で分かりやすく示す「プレゼンテーション」能力も身に付ける必要に迫られて
います。そこで、図解を使ってメッセージを分かりやすく伝える方法論から、最先端のデータビジュアライゼーションの現状までを盛り込んだムック「データプレゼンテーションの教科書」の一部を公開します。これこそデータを魅せるワザを習得できるベストプラクティスです。
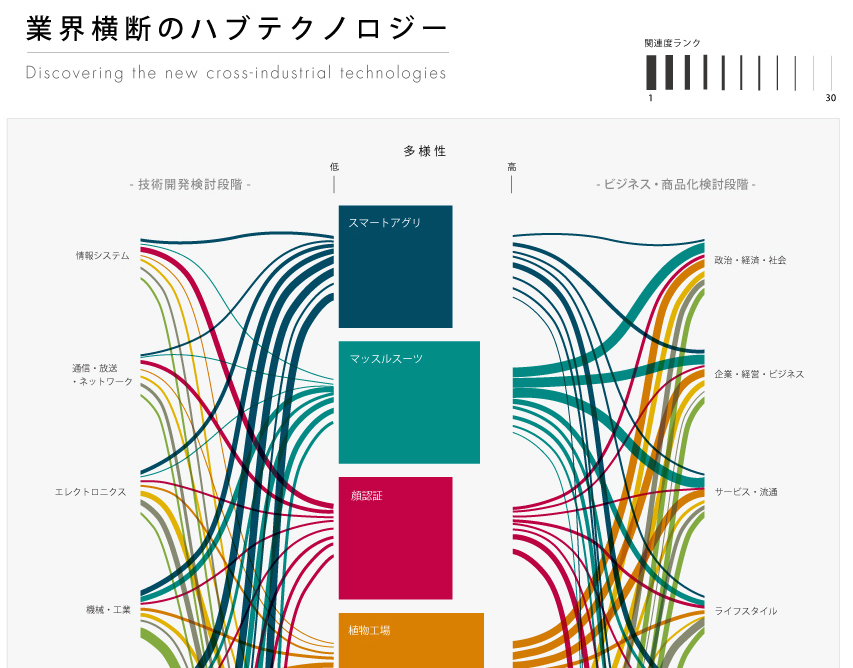
今回のお題は「多様性」です。今年もいろいろなテクノロジーが登場し、様々な記事が書かれました。「3Dプリンター」のようにより多くの業界と関連性が強いと判定されたテクノロジーは多様性が高く、逆に「バイオ医薬」のように少数の業界とだけ強い結びつきを持つものは多様性が低い。と考えられます。また、一方で、そもそもそのテクノロジーに関する記事がどれくらい書かれたのか、も、そのテクノロジーを評価する上で重要な指標でしょう。
今回の分析では既に業界IDでタグ付けされている過去記事をNikkeiBPさんからご提供いただきました。約15の業界について、合計10000記事以上の過去記事をいただき、プロセスしました。いきなりコードですが、今回はPandasとNumpyという、最近のPython分析の黄金標準的ツールを使いました。
import Pandas
import bumpy as np
data=[]
df1=pandas.io.parsers.read_csv('Articles.txt',header=0, sep='\t', na_values='')
df1['TitleBody']=df1['Title']+df1['Body']
np1=np.dstack((map(FreqDist,(map(tokens,map(striphtml,df1.TitleBody.values)[:END]))),\
map(splitcode,df1.L3.values[:END])))[0]
for i in np1:
if not i[1]: continue
for j in i[1]:
data.append((i[0], cat_name_dic[j]))
Pythonを使って極めて簡単にモデルを作成
このデータを使い、ナイーブベイズという手法で単語レベルでのトピックモデルを機械学習しました。ナイーブベイズとは、この手のトピックモデリング手法の中でも最もシンプルなもので、「単純ベイズ分類器」とも呼ばれます。確率論的に言うと、ドキュメントDがあった時に、そのドキュメントがカテゴリCに属する確率を計算するというのがこの問題の定式です。ベイズの定理を使うとこのようになります:
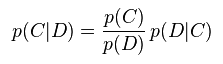
中でも右側の尤度p(D|C)の部分の計算が今回の学習部分から求められる。簡単に言うと、この業界に関しての記事にはこういう単語が使われる傾向にある、というモデルを作るという作業にを経て、p(D|C)は、このように表すことができる:

つまり、カテゴリCからDが生成される確率は、Dの中で使われている単語が、カテゴリCの中で使われている単語に近しいほど高い、という意味を持っている。これは非常に単純なモデルで、単語の並び順や文章の長さなど多くの文章解析的特性を無視しているが、それでもある程度の妥当性を持っている。今回は、自然言語処理ライブラリであるNLTKにこれに極めて近い実装があることがわかったのでほぼそのままこれを使いました。
import nltk
from nltk.classify import SklearnClassifier
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from nltk import compat
pipeline = Pipeline([('tfidf', TfidfTransformer()),
('chi2', SelectKBest(chi2, k=1000)),
('nb', MultinomialNB())])
classifier = SklearnClassifier(pipeline)
print 'training with data'
classifier.train(data)
ここにより詳細な説明があります:http://www.nltk.org/api/nltk.classify.html
上記、非常に簡単に書かれているが、先ほど説明した分類器がこれで定義されている。単語の出現回数をベースにしたTfidfという手法で書く単語の重み付けをし、各業界に対しトップ1000の単語だけでナイーブベイズ分類を行っています。
この分類器に対して、今度は各単語を含む記事を一つづつ分類にかけます。それぞれの記事がそれぞれのカテゴリに分類される確率を計算するため、最終的に書きだされるデータは記事数かけるカテゴリ数になります。下記のようなコードを使い、「カメリオ」で収集した全記事の中から、特定のワードが含まれるものに関して、分類器を使って確率を計算、CSV形式に書き出しました。
for id, title, body, d_p in get_contents_for_dates(date_from, date_to):
if title is None or body is None: continue
text=title+body
for i in match(syn_dic, text):
n_total[i]+=1
classified = classifier.prob_classify(FreqDist(tokens(striphtml(text))))
for j in classified.samples():
result= [i, word_dic[i].encode('utf-8'), n_total[i],\
id, cat_id_dic[j], j.encode('utf-8'), classified.prob(j)]
writer.writerow(result)
counter+=1
こうして出来たデータをTableauを使って分析したところ、下記のような結果が見られました。

右に行くほど多様性が高く、上に行くほど掲載記事数が多いテクノロジーです。掲載記事数は対数軸担っていますが、比較的強い相関が見られるのは、いろいろなところで書かれているものほどいろいろな文脈で書かれている、ということでしょう。
IoTやウェアラブルは騒がれているほどインパクトが大きくない?
そんな中で意外性があるのは右下と左上にあるものです。例えば、「量子アニーリング」は、量子コンピューターなどで最小値探索に使われる技術だということだが、様々な分野への応用があるようだ。「マッスルスーツ」も比較的多くの業界への関連が見られる。一方で、意外なのは、「ウェアラブル」と「IoT」である。どちらも今年大きなバズワードになった技術だが、いずれも多様性の軸で他の技術よりも劣っている感がある。ウェアラブルに関しては情報機器デバイスとしての話題に大きく偏っており、医療などの予想されていた分野への関連が案外弱い。またIoTに関しても、情報通信やオンラインサービス寄りの業界に強い関連が見られたが、それ以外の業界には相対的に関連性が低かった。
まとめ
今回は文書分類などに用いられる手法を使って、単語の「多様性」を指標化することに成功した。「カメリオ」のトピックモデルを使ってもこれに近いことができると思われるが、今回はビジネスにおける業界、に特化したお題に答えるために、独自のモデルを作ることになった。計算に特に時間がかかったのは、教師データの作成のところで(分かち書き等が含まれる)、実際の処理の際には一度読み込んだデータをpickleして書き出すことで、時間を短縮した。
妥当性と意外性の混在する結果が各テクノロジーの将来をどういうふうに示唆しているのか、今後の展開が楽しみなところです。
