こんにちは。データ解析担当の柴田です。
このたびNikkeiBPさんと強力でテキストマイニングのビジュアライゼーション作成のための分析を行いましたので、ご紹介します。ごく基本的な手法に最新の手法を加えることで、一段興味深い分析結果を出すことが出来ました。
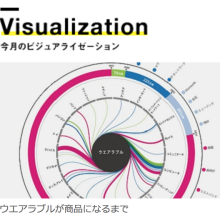 ビジュアライゼーションへのリンクはこちら
ビジュアライゼーションへのリンクはこちら
背景:「ウェアラブル」のトレンドってどう変化してきたの?
今回NikkeiBPさんからご相談を受けたのは日経ビッグデータにて毎月一回行われているコーナー、「今月のビジュアライゼーション」向けの分析です。今回頂いたお台は、「ウェアラブル」。今月はApple Watchの発表もあり、大きく盛り上がっているテーマです。今回日経BPさんの記事を元に、このテーマでどのようなトレンドの変遷があったのか、ビジュアライズしたい、というお代を頂きました。
データ:
頂いたデータは、日経BPの1999-2014までの全記事から、「ウエアラブル」もしくは「ウェアラブル」という単語を含むすべての記事です。期間ごとの記事数は
- 1995-1999: 70記事
- 2000-2004: 223記事
- 2005-2009: 202記事
- 2010-2014: 1815記事
となっており、近年特に関心の高まっている様子が分かりました。今回頂いたデータはこれだけです。そこからどんな分析が出来ることやら・・・
分析:
今回は頂いたデータがテキストだけということがあり、少し工夫をする必要がありました。今回利用したのはPythonの言語解析ライブラリ、Gensimです。自然言語処理に必要な基本的な統計処理に始まり、様々な分析手法が実装されています。言語処理に特化しているだけあって、基本的な分析は非常に簡単に行うことが出来ます。まず各年代ごとにBOWを生成します。articleクラスの中で分かち書きなどを行っていますが、そこでの前処理が終わればあとは一行で出来ました。
bow = dictionary.doc2bow(reduce(lambda x, y: x+y, \
map(lambda x: x.tokens_str_one, articles))
これが出来てしまうといろんなことが出来て、「ウェアラブル」という言葉のカウントをとるとすると
sum=0
for key, val in bow:
if dictionary.id_to_token[key].find(u'ウェアラブル')\
or dictionary.d_to_token[key].find(u'ウエアラブル'):
sum+=val
print 'total count was', sum
と言った感じで、非常にシンプルです。
今回、最近自然言語処理の研究分野を大きく変え始めたWord2Vecというニューラルネットを使った機械学習方法を使うことにしました。この手法は、文章を”読ませる”だけで、各単語の意味を空間の中のベクトルとして表現することが出来るようになります。そうすることで、例えば、この単語ににた単語は何か、とか、複数の単語郡の中にグループを見つけたりすることが簡単にできるようになります。
GensimでのWord2Vecの実装はとても使いやすく、
model = models.Word2Vec(tokens, size=50, window=5, min_count=1, workers=4)
try:
for i,j in model.most_similar(positive=[u'ウェアラブル', u'ウエアラブル'], negative=[]):
print i.encode('utf-8'), j
except KeyError:
print 'wearable was not found'
del model
とすると、その年代の記事から「ウェアラブル」に関連してどのような言葉が使われていたのかが分かるのです。今回は、データの量が少なかったため、ベクトル空間の次元を比較的少ない50に設定しました。一般的には200から500くらいの値が使われているようです。また引数から分かるように、複数スレッドに分けての分散処理にも対応しています。
動かすのが簡単な割に非常に示唆に富んだ結果を得ることが出来た!
1999年から2004年には「ウェアラブル」と関連度が高い単語として、「コンピューター」、「パソコン」、「ワイヤレス」、等の比較的表層的な技術名があがってきました。
↓
2000年から2009年の間は、「バイオ」、「健康管理」、「血圧」、「皮膚」等の言葉があがります。こういった用途での研究が進んでいたことが分かります。
↓
2009年から2004年の間は「腕時計」、「眼鏡」、「ブレスレット」、「指輪」等の言葉があがってきます。つまり、よりリアルなプロダクトが出てきたことが分かるのです。
Word2Vecは未だ研究段階という側面が強く、余り実世界への応用例は多くありませんが、今回の分析では、Word2Vecを使ってトピックのトレンドを読み出すことに成功しました。この手法をより多くのデータで応用することで、今後さらに面白いサービスなども作っていけるのではないかという気がします。
最後に
白ヤギコーポレーションからお知らせです。白ヤギコーポレーションでは、現在エンジニアを募集中です。弊社ではは今回の記事でも行われているような自然言語処理、機械学習、データ解析などのテクノロジーを使って、カメリオをはじめとした新しいメディアテクノロジーの開発を行っています。インターンからフルタイムまで幅広いオプションでのプロジェクト参加が可能ですので、興味のある方はぜひ、hr@shiroyagi.co.jpにお問い合わせください!
ご精読ありがとうございました。
