白ヤギの開発者の森本です。
白ヤギでは Go 言語でニュース記事のキュレーションをする カメリオ API というサービスを開発しています。約1年2ヶ月前、Go を使って開発し始めたときに当時調べた内容を整理して以下の記事を書きました。
1年以上に渡り開発を継続してきて変わったこと、変わってないことなどをざっくばらんにまとめてみます。たまたま過去の記事のはてブコメントを見返していて 以下のコメント を見つけました。
最近 golang 導入事例増えて来たけど、導入後一年くらいのメンテナンスフェーズな事例について聞いてみたい。継続的デリバリーみたいなの。まだ早いのかな?
まだまだメンテナンスフェーズにはなっていなくて現在も活発に開発中ですが、継続的デリバリーについて白ヤギでは特別なことをしてなく、ansible を使ってデプロイしているのみです。Go 1.6 からパッケージ管理の代替?となる vendoring 機能がデフォルトになっていて、いずれ対応しようとは考えていますが、白ヤギの用途ではパッケージ管理に困っていないので優先度は低いです。
API サービスも順調でここ半年ほどで数社の顧客に導入されています。導入事例をいくつか紹介します。
- 日経BP社様: nikkeiBPnetサイトリニューアルに伴い、全面採用されました。編集部×人工知能型エンジンでコンテンツ提供へ
- ディップ様: 「AINOW-世界初のAI専門メディア」
- au損保様: au損保の3アプリにカメリオAPIが導入されました
開発期間が1年以上になるにつれ、どのように開発が変わってきたかの変遷について書いてみます。コードの行数を数えてみると1万5千行 (テストコードを含めると2万5千行) ほどでした。開発規模は小さいのでちょっとした API サービスだと捉えてください。
開発環境
開発環境は以前と変わらず全く同じです。
- Go: バージョン 1.6.2
- Vim: テキストエディター
- vim-go: Go 開発向け IDE 環境 (各種ツールをまとめてインストールしてくれる)
- goenv: 仮想環境管理ツール
- fresh: 自動ビルドとサーバー再起動
- godep: 依存パッケージ解決
補足すると、Go のバージョンは新しいバージョンが出るごとに上げ続けています。1年前は 1.4.2 を使っていましたが、現在は 1.6.2 (8月上旬に 1.7 がリリース予定なので 1.6.3 は飛ばす) です。いつも新しいバージョンが出ると、ローカル環境で動作確認した後、すぐステージング環境に新しいバージョンをデプロイします。ステージング環境で1週間ほど動作させた後、問題がなければ本番環境にデプロイするようにしています。そうやってこの1年バージョンを上げ続けてきましたが、白ヤギの用途では Go のバージョンアップが原因で問題が発生したことは1度もありませんでした。
使っているライブラリ
いま API サーバーを開発するのに使っているライブラリです。
- binding: バリデーションライブラリ
- elastic: Elasticsearch クライアント
- go-mysql-driver: mysql ドライバー
- goji: 軽量 Web フレームワーク
- golang-stats-api-handler: サーバーのシステム情報を取得するライブラリ
- gorp: OR マッパー的なライブラリ
- ini: ini ファイルの読み書きライブラリ
- logrus: ロギングライブラリ
- redigo: Redis クライアント
- squirrel: SQL ジェネレーター
以下は以前に使っていたライブラリですが、別のライブラリに移行しました。
- configparser: ini ファイルパーサー
- context: context オブジェクトを扱うライブラリ (リクエストグローバル変数)
- negroni: HTTP ライブラリ
簡単に移行したライブラリとその理由について紹介します。
ini ファイルライブラリの移行
ini ファイルを読むライブラリを configparser から ini というライブラリに変更しました。ini ファイルの設定と Go の構造体とのマッピングを簡潔に実装できるので設定項目が増えたときのメンテナンスが容易になるという利点から変更しました。以下のサンプルコードは [Note] セクションを構造体にマッピングしています。例えば、この [Note] セクションに新しい項目が追加されても Note 構造体にメンバーを増やすのみで対応できます。
// Just map a section? Fine.
n := new(Note)
err = cfg.Section("Note").MapTo(n)
軽量 Web フレームワークの導入
昨年の秋頃に net/http の薄いラッパーライブラリであった Negroni から Goji に移行しました。
当時 Go のような若い言語で特定の Web フレームワークを使うのはリスクだという同僚からの反論もあったのですが、私の動機付けとしては Context オブジェクトは Web フレームワークと一緒に管理すべきだという設計方針がありました。もちろん Negroni でその仕組みを独自実装するという案もありましたが、それは Goji 相当のものを再発明するだけじゃないかという懸念もあり、Goji の採用に至りました。また Goji のサードパーティライブラリが使えるという利点もあります。白ヤギでも glogrus や cors などを使っています。
余談ですが、先月ユーリエの池内さん (@iktakahiro) に Go言語とReactで考える「いい感じなURL設計」 と題して 白ヤギが主催している勉強会 で発表して頂きました。
池内さんは Echo という軽量 Web フレームワークを採用していると発表されていました。私が Goji を採用した当時に Echo を見つけられていなかったのですが、これから採用するなら Echo も検討して良さそうです。パフォーマンスに重点を置くなら fasthttp に対応している数少ない Web フレームワークとしてもおもしろい存在です。
Goji も新しい機能は別リポジトリである github.com/goji/goji で開発を行うようです。Context オブジェクトに x/net/context を使っています。いずれ go 1.7 から標準ライブラリになる context パッケージに置き換えられるでしょう。また古い方の github.com/zenazn/goji もしばらくはメンテナンスを継続するとあります。
検索バックエンドとして Elasticsearch の導入
以前はカメリオのシステムを共有して使っていましたが、クラスタリング環境の管理/スケールの容易さ、コミュニティの盛り上がりなどから Elasticsearch に移行しました。それに伴い Elasticsearch クライアントとして Elastic というライブラリを採用しました。Elastic ライブラリについては以前にも Elasticsearch Advent Calendar 2015 向けに記事を書きました。
このライブラリについてもいくつか知見が溜まってきているのでいろいろ書きたいのですが、また別の記事にします。と言い続けてなかなか書かなかったりもするのですが、、、。
Web フレームワークとサーバーアーキテクチャ
1年以上、API サービスを開発してきて大きなアーキテクチャの変更が2回ありました。1つは上述した Negroni から Goji への移行です。もう1つは Goji のフレームワーク上にアプリケーション層というレイヤを構築したことです。以下はアーキテクチャの概念図です。
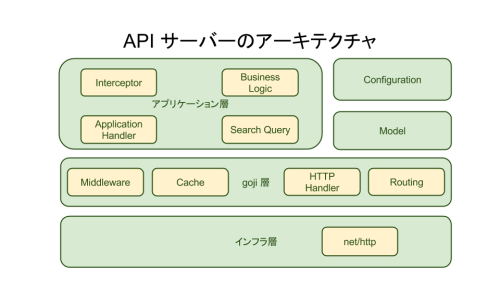
余談ですが、このアーキテクチャにおけるアプリケーション層は Java の Spring フレームワーク での開発経験から影響を受けています。DI (Dependency Injection) までは作り込んでいませんが、AOP (Aspect-oriented programming) の概念を取り入れています。
この階層構造により、例えば、認証やキャッシュの処理などといった API を横断的に行う処理は Goji 層のミドルウェアで行い、顧客=アプリケーションと見立て、顧客別のビジネスロジックはアプリケーション層のインターセプターで実現しています。Goji 層とアプリケーション層を分離したことで安定性や保守性を維持しつつ、機能の拡張性や柔軟性も確保しています。API サービスを利用している顧客が急増した今でもこのアーキテクチャは機能していてしばらくは大丈夫そうに考えています。
サービスのアーキテクチャを考えた場合、次に目立つのはモデルコンポーネントの貧弱さです。OR マーパー的な gorp と、squirrel という SQL ビルダーを組み合わせて実装していますが、言わば SQL を発行して Go の構造体にマッピングする薄いラッパーでしかありません。もし次に大きな変更をするとしたら、おそらく gorp と squirrel を別のものに置き換えて、モデルコンポーネントを作り直すことになると思います。
Goji のミドルウェアで足りない機能
多くの Web フレームワークではミドルウェアの仕組みを提供していると思います。Goji では Mux 単位にミドルウェアを設定する仕組みを提供していて、自分たちのアプリの用途として Mux 単位に任意の URL や URL 群を管理できるのであれば、標準のミドルウェア機能だけでも十分です。
とはいえ、例えばリソースを管理する CRUD な API を提供しようとしたとき、リソースの Create (POST メソッド) と Update (PUT メソッド) には検索インデックスの更新処理を、Retrieve (GET メソッド) は何もせず、Delete (DELETE メソッド) は削除処理を、といった要件に対してミドルウェアを適用するのは、がんばればそういった単位に Mux を分割して設定することもできますが、やや煩雑になりがちであるし、さらに他のミドルウェアとの連携を考慮するとすぐに破綻しそうにみえます。
白ヤギでは独自に MiddlewareDispatcher を定義して、ディスパッチ機能をもつミドルウェアを生成して登録します。以下はミドルウェアの生成メソッドです。
func (self *MiddlewareDispatcher) GetMiddleware() func(c *web.C, h http.Handler) http.Handler {
return func(c *web.C, h http.Handler) http.Handler {
fn := func(w http.ResponseWriter, r *http.Request) {
isDispatch, handlersKey := self.Dispatch(c, r)
if isDispatch {
for _, before := range self.GroupBeforeHandlers[handlersKey] {
if !before(*c, w, r) {
break
}
}
}
// must call regardless of MiddlewareDispatcher.Dispatch
// since http handler chain would be stopped
h.ServeHTTP(w, r)
if isDispatch {
for _, after := range self.GroupAfterHandlers[handlersKey] {
after(*c, w, r)
}
}
}
return http.HandlerFunc(fn)
}
}
MiddlewareDispatcher にはパスや HTTP メソッド、ハンドラー関数などセットした上で上記のメソッドを使って Mux にミドルウェアを登録します。
createTopicsDispatcher := NewMiddlewareDispatcher()
createTopicsDispatcher.SetHandlers(
PATH_TOPICS,
"POST",
handlers.CreateTopicsAPI,
[]BeforeHandler{},
[]AfterHandler{
createOrUpdateSearchIndex,
},
)
self.Mux.Use(createTopicsDispatcher.GetMiddleware())
この仕組み自体は非効率ではあるものの、このミドルウェア生成処理自体は安定しているので1年近く運用している中では保守や機能面で困ったことはありません。
その他に、私が知っている Goji のミドルウェア拡張としては kami があります。kami においても上述したミドルウェアグループによる管理は相互依存や組み合わせが煩雑になるという懸念から URL 階層に従うミドルウェアの仕組みを提供しています。また kami のミドルウェアは次に呼び出すハンドラーを返すのではなく、Context オブジェクトを返すかどうかでミドルウェアの実行制御をしています。
2016-08-09 追記
設計に関してイベントで発表したスライドを以下で公開しています。
テスト
テストの仕組みは1年前と変わっていません。
基本的には TableDrivenTests で単体テストを書いています。それでも何とかなっていると言えば何とかなっていますし、テストコードという特性上、優先度が低いので単に変えていないだけだったりもします。勉強会などでは testify を使っている事例をちょくちょく聞くのでいずれはこのライブラリを使おうかと検討していたりもします。
Python と Go
前回の記事でも書きました。あれから1年経ってどんな雰囲気になってきたかをいくつかの記事を紹介しながら考えてみます。と、いろんな記事を紹介しながら書き始めたらいろんな話題がごちゃ混ぜになっています。あくまで私個人が見聞きした記事から紹介しているのである程度は偏っているという前提で興味のあるところだけ参考にしてください。
Go への批判
ちょくちょく見かけるようになってきたと思います。それだけ Go 言語が多くの開発者に普及したという証拠でもあると私は思っています。
github に “Go はそれほど良くないよ” と銘打ったまとめ一覧があります。
このまとめ一覧から接頭辞が no で始まるものを抜き出してみます。
no constructors
no user-type iteration
no OOP
no language interoperability (only C)
no versioning model
no function/operator overloading
no exceptions
no generics
no immutables
no pattern matching
no decent IDE
no map/reduce/filter
no subpackages
no first-class support of interfaces
no unused imports
no ternary operator
no macros or templates
no virtual functions
こうやって抜き出してみると、いろいろあるもんですね。
まずジェネリクスは既に提案がされていて、もしかしたら次のメジャーバージョン Go 2.0 のときに採用されるかもしれません。
私の用途だと、ジェネリクス以外のものはなくても開発に困っていなかったりはします。強いて言えば、三項演算子があると嬉しいですが、それはコーディングスタイルの好みです。
ジェネリクスの代替として interface を使うサンプルが紹介されている記事を見かけた人も多いでしょう。例えば、sort パッケージのソースをみると、sort.Interface が以下のように定義されていて、一部のソート処理のサンプルを抜き出すとこんな感じに実装しています。
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
func Sort(data Interface) {
// Switch to heapsort if depth of 2*ceil(lg(n+1)) is reached.
n := data.Len()
maxDepth := 0
for i := n; i > 0; i >>= 1 {
maxDepth++
}
maxDepth *= 2
quickSort(data, 0, n, maxDepth)
}
// Insertion sort
func insertionSort(data Interface, a, b int) {
for i := a + 1; i < b; i++ {
for j := i; j > a && data.Less(j, j-1); j-- {
data.Swap(j, j-1)
}
}
}
確かに interface で実装はできますが、数値型のサイズ違いのとき、プリミティブ型のエイリアスとして独自型を定義したときなど、毎回 interface を定義してそれぞれにほとんど同じようなコードを実装するのはちょっとうんざりしますし、DRY 原則にも違反してしまいます。
たまたま調べていて見つけたのですが、Go 言語の開発者である Russ Cox 氏の過去のブログ記事 The Generic Dilemma に、ジェネリクスにまつわるプログラマーの生産性、言語の複雑性、コンパイル速度、実行速度のそれぞれのトレードオフのような葛藤が書かれていておもしろかったです。興味があればそちらも参考にしてください。
Go のプラクティス
批判を見かけるようになった一方でプラクティスも洗練されてきたように思います。
開発全体に関するプラクティス
開発しているものがバイナリとして使うものか、ライブラリとして使うものかでリポジトリ構造を変えるというプラクティスが私は参考になりました。白ヤギでは API サーバーという単一リポジトリのみで開発しているのですが、そろそろライブラリ類を分割しても良いかもしれないと考えている頃です。Go のコンパイルは速いと言っても、やはりコードベースが大きくなるにつれて徐々に遅くはなっていくのでライブラリとしてリポジトリ分割する際に役立ちそうです。
またテストフレームワークやライブラリに関しては以下のようにばっさりですね。
2014年、私は様々なテスト用フレームワークとヘルパーライブラリを使った経験を振り返り、1つとして使えるものはないという結論に達して、stdlibのアプローチであるテーブルベースの平易なパッケージテストを薦めることにしました。
と、この記事の著者は主張していますが、私はここで言うテーブルベースの平易なテストのみをずっと書いてきてもう疲れました。また記事の中ではテストしやすいコードのための設計として関数型のスタイルで書くことが最善である (と思われる) と推奨しています。これは Go 言語に限ったものではなく、他の言語でも共通のプラクティスな気がします。
あまり見かけないもので、私が開発してきて思うプラクティスの1つは、Named result parameters (名前付き結果パラメーター) を多用することです。CodeReviewComments#named-result-parameters から簡単に抜粋してみます。以下はこの wiki で名前付き結果パラメーターの使用例として紹介されているサンプルコードです。
// Location returns f's latitude and longitude. // Negative values mean south and west, respectively. func (f *Foo) Location() (lat, long float64, err error)
- 関数の返り値が型のみだと結果が不明瞭なときは名前を使う
- 関数が数行のときは使っても良い
- 中ぐらいのサイズの関数なら明示的に返り値を返す方が良い
- 単に
returnと書きたいだけならその価値はない - deferred closure の中でその名前を変えたいときに使うのは良い
と、このコメントを読む限りでは多用することを推奨してはいません。私も明示するコードを書くスタイルを好むので当初は名前付き結果パラメーターを使っていませんでした。開発をしていて徐々に名前付き結果パラメーターを多用した方が良いと考えるように至った理由は以下になります。
- 返り値に名前をつけた方が関数のシグネチャとして分かりやすい
- Go は言語仕様として zero value が定められているため、エラーなどの条件分岐で return する値を統一できる
- 条件分岐で return するようなとき、分岐ごとにその初期化コードを書く必要がない (オブジェクトを返すときは冗長になりがち?)
- ある条件のときにその関数の返り値を調べるときにコードが読みやすい (と思う)
- 名前付き結果パラメーターがある関数とない関数が混在している状態そのものが統合性がなく何となく気持ち悪い (と思う)
名前付き結果パラメーターを多用するというのは私の主観なのでご参考まで。
パフォーマンスに関するプラクティス
GolangRdyJp を眺めていて興味深かったので紹介します。
白ヤギではまだ機能優先の段階であり、パフォーマンスの考慮は後回しになっていたりします。アプリに応じた最適化をするには適切なテストとプロファイルを取ることが必要になります。こういった Tips は、どこから最適化していくかの取っ掛かりになるのでとても参考になります。
Go のエラー処理
私はイベントの抽選に外れて参加できなかったので発表そのものは聞いていないのですが、キーノートスピーカーの Dave Cheney 氏のスライドをみると Go のエラー処理について発表されていたようです。余談ですが、先日 『プログラミング言語Go』刊行記念イベント に参加してきたのですが、そのトークセッションの中でも鵜飼氏が「Go はエラーの扱いが特徴的だ」と話されていたのが私の記憶に残っています。
さて、Dave 氏のスライドでは Go のエラー処理を3つの種別に分けて考察しています。
- Sentinel errors
- Error Types
error の値により処理を続行するか中止するかといったエラー処理を行う方法です。
io.EOF や syscall.ENOENT などが例として紹介されています。また error interface の Error() メソッドは、コード上で使うものではなく人間向けにログ出力や画面に出力するための文字列なので決して検査しようとしてはいけないとあります。結論としてこのようなエラー処理は避けるべきだと主張しています。
独自エラー型を定義して型アサーションや型 switch を使ってエラー処理を行う方法です。
os.PathError が標準の error を内包して付加情報を返す良い例だと紹介しています。
// PathError records an error and the operation and file path that caused it.
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
Sentinel errors よりはこちらの方が良いが、エラー値の多くの情報を共有してしまうところに懸念があるため、結論としてこれも避けるべきだと主張しています。
エラーの中身を知る必要はなく、エラーが発生したという事実をもってエラー処理を行う方法です。
import "github.com/quux/bar"
func fn() error {
x, err := bar.Foo()
if err != nil {
return err
}
// use x
}
Go で開発しているとこのエラー処理の方法が一般的であるように思います。呼び出し側はエラーが発生したとかどうかのみを判別し、Foo() メソッドはどんなエラーを返すのかを保証しなくて済むというのが利点だとあります。
これらから Go の格言を紹介されていました。
Don’t just check errors, handle them gracefully.
Dave 氏の発表の後半に出てくる pkg/errors というライブラリについては Golangのエラー処理とpkg/errors の記事で詳しく解説されていて参考になります。
pkg/errors ライブラリでは、Wrap() と Cause() というメソッドでエラーを扱います。
_, err := ioutil.ReadAll(r)
if err != nil {
return errors.Wrap(err, "read failed")
}
type causer interface {
Cause() error
}
switch err := errors.Cause(err).(type) {
case *MyError:
// handle specifically
default:
// unknown error
}
Java の例外チェーン機能 を知っていれば、この概念は受け入れやすいものだと思います。Python においても PEP-3134 で提案され、Python3 からこの機能が提供されています。Java/Python の場合、これらが言語機能に組み込まれている利点としては、スタックトレース情報を自動的に保持してくれたり、標準化されていることで例外情報の扱いがライブラリ依存にならなくて済むといったところでしょうか。
Stack Overflow でも Go 言語で例外チェーンはどうやるの?といった質問を見かけた (そういう機能はないという回答) のですが、言語機能 (もしくは標準ライブラリ) として提供するといった議論はあるのでしょうかね?私が簡単に調べた限りでは分かりませんでした。
Go から Python へ移行した話
1年前は Python から Go への移行が目立っていましたが、最近はその逆もたまに見かけるようになってきました。Python と Go、どちらの言語を選択するかの最も大きな要素は並行性や実行速度に関するものだと思います。Go を試してみた上で実行速度が絶対要件ではないものは Python の方が嬉しい場合があると表明する開発者が出てきました。
このスライドのパフォーマンスのところを抜き出してみます。
- 一般的に Go は CPython より50-100倍速い
- PyPy は CPython より5-25倍速い
- Go の2-10倍の (実行速度という) 範囲内であれば50-100倍に比べれば多くの用途で許容できる
- Go SSL はピュア Go で実装されている (CPU 負荷が高い、最近の Go はこれを改善している、Cloudflare はマージできない Intel SSL アセンブラコードを用いて大きな改善を行った)
- PyPy は Game Changer (ものごとを大きく変える存在) だ
ちゃんと調べていないのですが、SSL の話題は Go crypto: bridging the performance gap の記事を指していると思います。比較対象が Go 1.4.2 なのでやや古い記事であるのに注意してください。
閑話休題。PyPy の存在により Go と比べて2-10倍遅い程度なら許容できる場合が多くあると書かれています。PyPy は良い選択肢だと思うのですが、1つ懸念なのは Python 3 互換である PyPy3 の開発がやや停滞気味にみえるところです。現在は 3.3.5 互換のアルファバージョンが公開されています。
こちらの記事は asciinema というターミナルセッションを記録するアプリ開発で Go 実装から Python 実装に変更したというものです。Go の良さも認めつつ Python に切り替えた理由として以下が挙げられています。
- 並行性や速度を必要としていない
- Python が高レベル言語であるのに対して Go は低レベル言語です (C言語 2.0 と言うのは正しいと私は思う)。asciinema のコードベースの 95% は高レベルのコードであり、基本的に1つのファイルに select/signal/ioctl/fork のようなシステムコールを含む
- ビルドの問題: Go 関連の pty/terminal ライブラリは多くのアーキテクチャや OS をサポートしないのに対して、Python は全ての UNIX ライクなシステムで動作する
- パッケージのバージョン管理がない、中央リポジトリがないといった Go の機能不足はパッケージ管理を面倒にする
- バッテリーインクルード: asciinema では argparse, pty, locale, configparser, json, uuid, http といった Python の素晴らしい標準ライブラリを使っている
- ネイティブパッケージのメンテナーにとって外部依存関係が少ないほど嬉しい。現時点では asciinema の外部依存パッケージはゼロです!
- int32 を int64 にキャストするのにすぐ飽きる
if err != nil {と書くのにすぐ飽きる
このアプリの開発者にとって、アプリの特性を考慮した結果、Go よりも Python の方に開発上のメリットがあるというように読めます。
Go で Python モジュールを開発する
PyCon 2016 のスケジュールを眺めていて以下の発表を見つけました。
Go と Python はそれぞれ C 言語とやり取りできるのに着目し、C 言語を経由してそれぞれの言語のランタイムバリアを超えられるのではないかという考察です。Go から C 言語とやり取りするためのパッケージとして cgo があります。一方、Python から C 言語とやり取りする方法はいくつかありますが、ここでは CFFI (C Foreign Function Interface) を使っています。
実用性はともかく、技術的な興味としておもしろいです。Python の開発者はその文化的な類似性から Go の開発に馴染みやすいと思います。私のように Python でちょっとした Web アプリやツールを作ったりしつつ、Go でサーバーサイドの開発をしているプログラマーはたくさんいるように思います。実際に動くサンプルモジュールを作って Go の net/http と比べて遜色ないパフォーマンスのベンチマーク結果も掲載されています。
まとめ
この読み難いテンプレートの、読み難い構成の、だらだら長い記事を最後まで読んで頂いてありがとうございます。
私はもう1年以上 Go 言語で API サーバーを開発しています。サービスが1年分大きくなった今でも特に困ることなく開発を継続しています。本稿の中でいくつもプラクティスを紹介したのですが、ビルドやデプロイも含め、まだまだ自分たちのプロダクトに活かせていないところがあるのが現状です。私自身 Go の機能や設計哲学、その開発文化などを学びながら、まだまだサービスを成長させる余地があるように考えています。
最後に白ヤギコーポレーションでは一緒に API サービスを開発/運用してくれるエンジニアを募集しています。Go でプロダクト開発をしてみたい方、ぜひご応募ください。
