はじめに
こんにちは、カメリオのアルゴリズムとサーバ周りを担当している金子です。
白ヤギでは、カメリオのテーマに表示される記事の精度を向上させるために日頃から様々な研究を行っています。現在特に注目しているのは word embedding を用いる方法です。 word embedding は単語や文書の意味を比較的低次元のベクトルで表すことができ、ベクトル同士の演算によって意味的な関係性を扱えるという特徴があります。
word2vec は word embedding の代表的なアルゴリズムです。 word2vec には様々な実装がありますが、それらの比較はあまり行われていないようでした。今後のことを考えると、特にライブラリ選択の上でパフォーマンスについて知っておく必要があったため、今回以下のソフトウェアを比較しました。
- word2vec
- word2vec_cbow
- gensim の Word2Vec クラス
- TensorFlow の word2vec サンプル
- DMTK の distributed_word_embedding
- Chainer の word2vec サンプル
(なお、これ以降 word2vec は手法全般のことではなく上記のソフトウェアとしての word2vec を指すものとします)
実験結果
まず先に実験結果を示します。
CPU を使った結果
| 名前 | 実行時間 | 処理速度 (K words/sec) |
|---|---|---|
| word2vec | 5m34.419s | 749.91 |
| gensim 0.12.3 | 5m55.024s | 718.48 |
| TensorFlow 0.6.0 | 29m57.026s | 141.94 |
| DMTK | 22m48.529s | 186.39 |
| chainer 1.5 | N/A | 4.78* |
| chainer improve-word2vec | N/A | 5.41* |
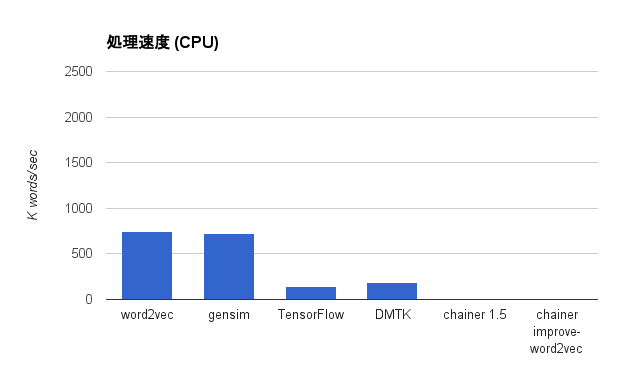
word2vec と gensim がほぼ同じ速度、次いで DMTK 、 TensorFlow の順に速いという結果になっています。 Chainer は時間がかかりすぎて終わらなかったので、途中経過からの概算で処理速度を出しています。
GPU を使った結果
| 名前 | 実行時間 | 処理速度 (K words/sec) |
|---|---|---|
| word2vec_cbow | 1m52.208s | 2234.98 |
| chainer 1.5 | 117m47.879s | 36.09 |
| chainer improve-word2vec | 80m8.459s | 53.05 |
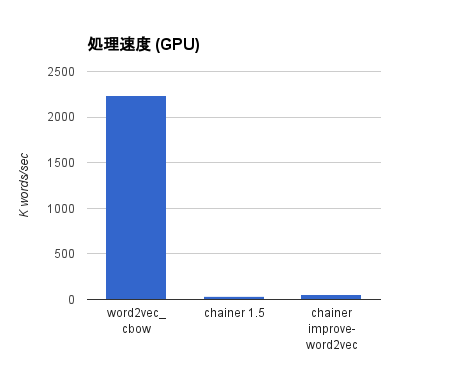
word2vec_cbow はさすがに GPU を使うだけあって元になった word2vec に比べて3倍以上高速になっています。 chainer は GPU を使うとだいぶマシになりますが、それでもかなり遅いです。ただ、 improve-word2vec ブランチの実装では、 Chainer 1.5 のものと比べて速度が1.5倍程度に改善されています(ここには示していませんが、条件によっては2倍以上の性能が出ることもありました)。残念ながらまだマージされていませんが、次のバージョンにはぜひ入ってほしいですね。
まとめ
この結果を見る限り、速度に関する比較だけで言えば word2vec か gensim のどちらかを使っておけば良さそうです。 word2vec_cbow は速いですが、 GPU が必要なので動かせる環境が限定されてしまいます。逆にどうしても高速化したい場合には良い選択肢だと思います。
TensorFlow, DMTK, Chainer は期待していたのですが、速度面でこれだけ差がついてしまうと厳しいものがあります。これらは主として深層学習の様々なアルゴリズムを簡単に実装するためのフレームワークなので、プロトタイピングには向いていますが、特定のアルゴリズムに特化したライブラリと比べるとオーバーヘッドは大きいようです。
実験詳細
全体で共通するパラメータは以下の通りです:
- ベクトルサイズ: 200次元
- 学習モデル: CBOW (TensorFlow のみ Skip-gram)
- 出力モデル: ネガティブサンプリング
学習には text8 コーパス (単語数: 17,005,207; サイズ: 約96MB) を用いました。コーパス中の全単語を15回繰り返して学習しています。
実行環境は AWS の c4.2xlarge (8 CPU, メモリ 15GB) および g2.2xlarge (8 CPU, メモリ 15GB, VRAM 4GB, CUDA コア数 1,536) です。
実験に用いたスクリプトはここにあります: https://bitbucket.org/knzm/wordembedding-experiments
環境構築に関する詳細はこの記事とは別に後日公開する予定です。
(2016/1/13 追記) 公開しました!
- for Ubuntu 14.04 に Chainer, TensorFlow, DMTK をインストールする (GPU 有効) – Qiita
- for Mac (El Capitan) に Chainer, TensorFlow, DMTK をインストールする – Qiita
word2vec
Mikolov のオリジナルの実装です。 CPU のみで高速に動作します。 C で実装されています。
パラメータ:
- ベクトルサイズ: 200次元
- 学習モデル: CBOW (ウィンドウサイズ: 8)
- 出力モデル: ネガティブサンプリング (サンプリング数: 25)
- ダウンサンプリング: 10^-4
- 対象単語: コーパス中の出現回数5回以上の単語
- スレッド: 20
word2vec_cbow
オリジナルの word2vec を CUDA に移植したものです。 GPU がないと動きません。 C で実装されています。
パラメータは word2vec と共通です。
gensim
gensim という Python で書かれたトピックモデルのためのライブラリがあり、この中に word2vec の実装が含まれています。 GPU には対応していません。 Python で実装されています。
- ベクトルサイズ: 200次元
- 学習モデル: CBOW (ウィンドウサイズ: 8)
- 出力モデル: ネガティブサンプリング (サンプリング数: 25)
- ダウンサンプリング: 10^-4
- 対象単語: コーパス中の出現回数5回以上の単語
- スレッド: 20
TensorFlow
Google が公開している機械学習用のフレームワークです。 TensorFlow 自身は CPU/GPU に両対応していますが、 GPU では “Cannot assign a device to node” というエラー (注1) で word2vec が動かなかったため CPU のみの結果となっています。 C++ と Python で実装されています。
元の実装では 128 単語 * 100,001 回の繰り返しで終了するようになっていたので、他の実装と条件を合わせるためにコーパス中の全単語を 15 回繰り返すように修正しました。
パラメータ:
- ベクトルサイズ: 200次元
- 学習モデル: Skip-gram
- 出力モデル: ネガティブサンプリング (サンプリング数: 64)
- 対象単語: コーパス中の出現回数5回以上の単語
- ミニバッチサイズ: 10,000
(注1) おそらく原因はこれです https://github.com/tensorflow/tensorflow/issues/514
DMTK
Microsoft が公開している機械学習用のフレームワークで、正式名称は Distributed Machine Learning Toolkit といいます。 DMTK 上で動く word embedding の実装が公開されています。 DMTK は CPU のみで動きます。 C++ で実装されています。
DMTK には word2vec 以外に Distributed Multi-sense Word Embedding という、単語が複数の意味を持つことを考慮したモデルがあって、こちらを是非試してみたかったのですが、うまく動かなかったので今回は比較対象には含まれていません。
パラメータ:
- ベクトルサイズ: 200次元
- 学習モデル: CBOW (ウィンドウサイズ: 8)
- 出力モデル: ネガティブサンプリング (サンプリング数: 25)
- 対象単語: コーパス中の出現回数5回以上の単語
- スレッド: 16
Chainer
Preferred Networks が公開している機械学習用のライブラリです。 Python で実装されており、 cupy というライブラリを使って CPU/GPU 両対応しています。
なお Improve word2vec #641 に word2vec を高速化したブランチがあるので、そちらも併せて比較しています。
パラメータ:
- ベクトルサイズ: 200次元
- 学習モデル: CBOW (ウィンドウサイズ: 8)
- 出力モデル: ネガティブサンプリング (サンプリング数: 25)
- 対象単語: コーパス中の全単語
- ミニバッチサイズ: 100,000 (CPU) / 50,000 (GPU)
なお、 Chainer はミニバッチサイズを大きくすると高速化します。 VRAM が許す限り大きな値を指定すると良いです。
おわりに
近頃では機械学習という言葉が技術系だけでなく一般のニュースでもよく聞かれるようになり、いよいよ一般化してきた印象があります。ここ最近では Google と Microsoft が立て続けに機械学習ライブラリを公開したり、 CPU と GPU を両方扱える Chainer のようなライブラリが増えてきたりと、機械学習を取り巻く環境は格段に良くなっています。しかし、試しに使ってみる以上のことをしようとすると、まだまだ情報が不足しているのが現状ではないかと思います。この記事が何かの参考になれば幸いです。
