こんにちは、シバタアキラです。この度PyDataの本家であるアメリカのコミュニティーで半年に一度開催されているPyDataカンファレンスに出席するため、NYCに行って来ました。11/22-11/23の二日間の日程で行われ、延べ250人ほどが参加したイベントです。その時の模様は、先日のPyData Tokyo第二回ミートアップでもご説明させていただき、また後日記事化されると思いますので、そちらをぜひご覧いただければと思います。
今回はそのPyData NYCカンファレンスで私が発表してきたミニプロジェクトについてお話します。最近各所で話題に上がるディープラーニングですが、これを使った応用を「カメリオ」のサービス向上のために使えないか、というのがそもそものプロジェクトの着想でした。今回PyData Tokyoオーガナイザーとして、またディープラーニングで色々と面白い実験をしている田中さん(@atelierhide)にもご協力いただきました。
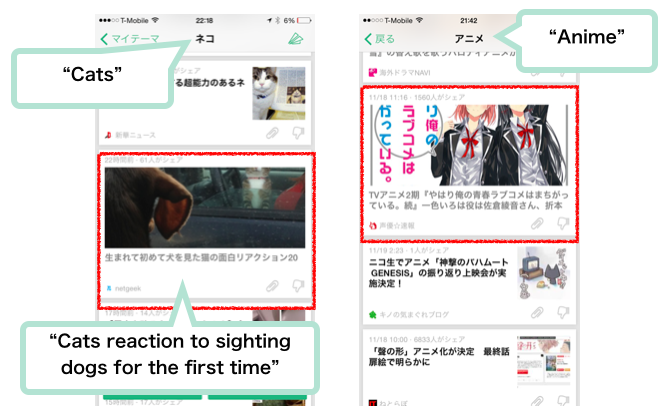
カメリオでは、記事の見出し表示の際に、非常に横長のサムネイルを使っています。
記事は、
- http://netgeek.biz/archives/25449
- http://seiyuusokuhou.blog106.fc2.com/blog-entry-10356.html
から転載しています。
その際に問題なのが、画像切り抜きの位置です。原稿では非常に簡略なルールを使っており、イメージの中央部分の切り出しを使っているのですが、上の例のように重要な部分(左ではネコ、右では人の顔)が隠れてしまうという問題が有りました。そこで今回、ディープラーニングの物体認識を使い、特に人間にとって重要と思われる部分を切り取らないようなサムネイルの生成ができないかということに挑戦しました。
まずは画像から認識領域の切り出しが必要
まず、ディープラーニングによる物体認識の前に、物体認識をかける画像領域の切り出しが必要です。これには以前はSliding Windowというアルゴリズムを使い、様々なサイズ、位置、アスペクト、などをBrute Force的に抽出して、使うというものが有りましたが、領域の下図が非常に多くなる欠点がありました。それに対し、最近ではイメージのセグメンテーションを使ったSelective Searchという手法が注目されています。セグメンテーションとはイメージの中の似たような領域を一つの物体として認識し、またその認識におけるアルゴリズムやパラメーターを変化することで、様々な物体の候補を提案するという手法です。ここに、以前の手法との比較など、より詳細な検証が書かれています。
Facebookのリサーチサイエンティスト、Piotr Dollár氏の記事:http://pdollar.wordpress.com/2013/12/22/generating-object-proposals/
この手法は、オランダの研究者のKoen van de Sande氏等によって開発されたもので、Matlabのコードが公開されています:
http://koen.me/research/selectivesearch/
今回は、このコードを走らせ、ScipyのIOモジュールでアウトプットを拾い上げました。実際には、Pythonのサブプロセスとして走らせた状態で、ラッパーなどは存在していません。こんなかんじです
pid = subprocess.Popen(shlex.split(mc),stdout=open('/dev/null', 'w'), cwd=script_dirname)
matlab -nojvm -r "try; selective_search({‘image_file.jpg’},‘output.mat'); catch; exit; end; exit"
all_boxes = list(scipy.io.loadmat(‘output.mat')['all_boxes'][0])
subtractor = np.array((1, 1, 0, 0))[np.newaxis, :]
all_boxes = [boxes - subtractor for boxes in all_boxes]
こうやって取り出された”box”を見てみると、このように大量に生成されていることがわかります。大体一つのイメージに対して200位の候補領域が出力されます。

いよいよディープラーニングによる物体認識
このそれぞれの領域に対して、ディープラーニングを使った物体認識を行います。今回使ったのは、PyData Tokyo第一回ミートアップでもPFNの大野さんが紹介していたCaffeというライブラリー及びImageNet2013の教師データを使ってトレーニング済みのネットワーク定義です。Caffeの素晴らしいのは、このようにして様々な教師データを使ってトレーニングの行われたネットワークが、Model Zooで共有されており、非常に高度なトレーニング結果を、そのまま使うことができます。ImageNet2013の物体認識は、200種類の物体カテゴリーが用意されており、その中には、「人間」、「ネコ」などから「マイク」「消しゴム」まで幅広く用意されています。インストールには若干手間取りますが、それが終われば使い方わ極めてシンプルです。
MODEL_FILE=‘models/bvlc_…_ilsvrc13/deploy.prototxt’ PRETRAINED_FILE = ‘models/…/bvlc_…_ilsvrc13.caffemodel’ MEAN_FILE = 'caffe/imagenet/ilsvrc_2012_mean.npy' detector = caffe.Detector(MODEL_FILE, PRETRAINED_FILE, mean=np.load(MEAN_FILE), raw_scale=255, channel_swap=[2,1,0])
前述の候補領域から特に面白い物体があると判別された上位の領域だけを取り出したものがこれです:

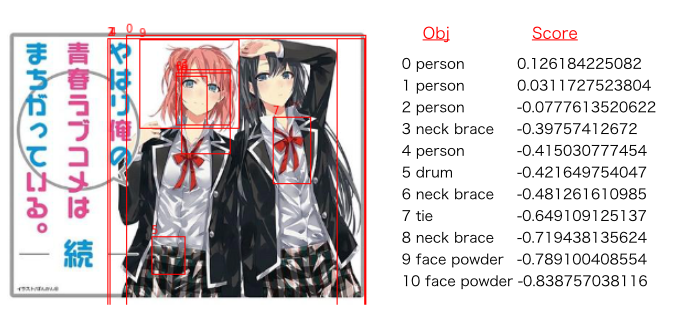
スコアが高く特に上位にある領域は、「ネコ」や「人」などに正しく分類されているのがわかります。女の子のネクタイや、顔の「フェイスパウダー」などまで特定されているのは驚異的としか言いようがありません。
ついに、「面白さ」ヒートマップの完成
今回はこのスコアを確率値として解釈するために、ざっくりとexp(score)と置き、すべての領域に対してスコアを合算しました。どう見ても物体の入っていないものや間違って認識されているものも入りますが、スコアは非常に小さい傾向にあったためそのまま使いました。そのようにしてできたのが下図です:
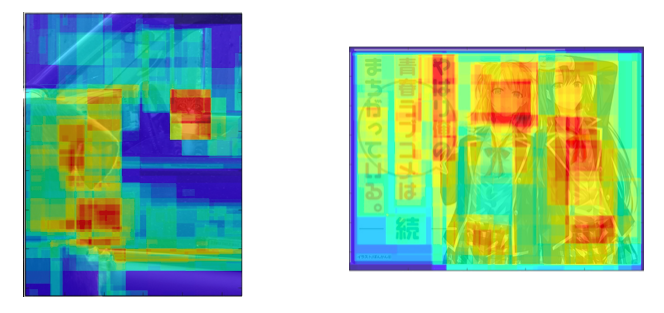
ネコや人などが特に赤くなっているのがわかります。これは人間が見た時の「面白さのヒートマップ」と解釈することができ、とても斬新です。様々な応用が考えられます。一方で、右図に関しては文字周辺も赤くなっており、このような部分に関しては今後にも課題が残ります。
今回は画像の切り取りが目的だったため、もっとも面白さの高い部分を中心に含む切り取り領域を探索しました。Numpyを使うとこんなかんじです。
#サムネイル化可能なすべての領域を指定されたサイズで生成
while y+hws <= h:
while x+hws <= w:
window_locs = np.vstack((window_locs, [x, y, x+hws, y+hws]))
#それぞれの領域について、最も面白い領域が中心にあるほど小さなスコアをアサイン
for i, window_loc in enumerate(window_locs):
x1, y1, x2, y2 = window_loc
if max_val != np.max(arr_con[y1:y2, x1:x2]):
scores[i]=np.nan
else:
scores[i] = ((x1+x2)/2.-xp)**2+ ((y1+y2)/2.-yp)**2
#スコアが最小のものを最終的に切り出し
img_pil = Image.open(fn)
crop_area=map(lambda x: int(x), window_locs[scores.argmin()])
img_crop = img_pil.crop(crop_area)
このようにして、人の目から見てもベストと思われる領域の抽出に成功しました。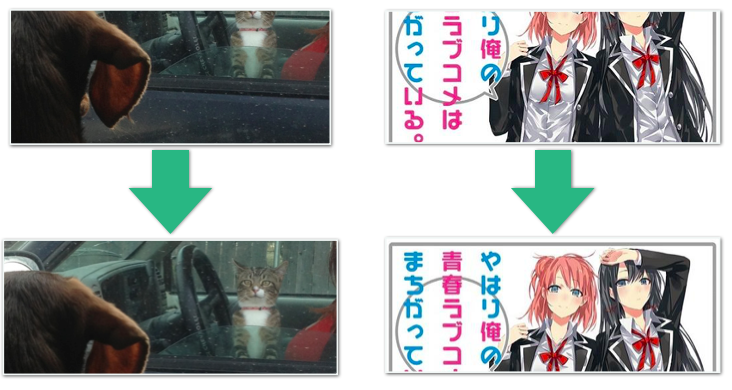
今回の手法は非常に新しいテクノロジーを取り入れ、満足度の高い結果に持って行くことができた点で大きな成功でした。一方で、処理の速度には大きな課題が残ります。というのも、標準的なCPUを使うと、一枚の写真を処理するのに、数分かかってしまうのです。特に処理時間の大半を占めるCaffeはGPUでの動作をさせたり、スピードアップをすることが可能なため、そのような形で今後実用化を検討していきたいと思っています。
最後に、今回PyData NYCで発表したスライドをこちらにアップロードしましたので、御覧ください。
