前回の更新から一ヶ月以上経ってしまいました。AIALでは、来る新情報吸収サービスBizzlioリリースに向けて毎日ハードな研究開発の日々です。
AIALの開発環境のメインはパイソンというスクリプティング言語です。研究所長の研究経験から引き継いだ選択でしたが、実際に科学計算用のアルゴリズムに強力な言語です。スクリプティング言語としての開発の速さはもちろんですが、内部のオプティマイズの進んでいる部分も多く、例えばNumpyやScipyなどのツールキットはC言語(Scipy一部のパッケージはなんとFortran)で書かれているため、爆速で動きます。更に最近ではCythonやPypyなどの仕掛けで、パイソンで書いたコードをC言語としてコンパイル出来たりしてしまうので、AIALでも今後積極的に取り入れていく予定です。
そんなパイソンの開発者コミュニティーの国際会議が週末に行われ、意外にも(?)500人を超えるパイソン開発者が参加しました。パイソン言語の開発者が所属することでも有名なDropBoxからもエンジニアの方がLinux向けDropBoxの開発について公演されたり、盛りだくさんの会合になりました。

台風の中、最終日月曜日に行われたハッカソンにはチーム白ヤギも参加しました。この日のために用意したプロジェクトはズバリ「日本語の可視化」
Visualizing Language
(English follows)
日本語の単語の関係性をグラフDBでモデル化します (日本語でなくても動くはず)
文章の構造を理解する上で、単語同士の関係性を理解することは非常に重要です。具体的には
- 関連語:同じドキュメントに出現する事が多い単語 (例:「オリンピック」と「滝川クリステル」)
- 派生語:同じ単語を含む派生的な単語 (例:「グラフ」と「グラフデータベース」)
- 類語:似たことを意味するが別の単語 (例:「シンプル」と「簡単」)
などが考えられます。単語同士の関係がわかると、サーチやレコメンデーションに非常に有効です。例えば、パイソンのことを気にしている人はDropBoxについても気になるだろう、とか、台風のことを気にしていたら竜巻のことも気になるだろう、とか。
今回は私がニュース記事から収集した書く記事の単語リストを入力データとし、そこから単語同士の関連性を抽出し、グラフデータベースに入力することで、日本語を可視化してみたいと思います。
具体的にはNeo4Jというグラフデータベースが結構充実しているようなので、これのパイソンAPIを使いたいと思います。
- 使い方のチュートリアルはここ:http://www.coolgarif.com/brain-food/getting-started-with-neo4j-part2
- 若しくはPy2NeoというAPIもよさそうです:http://blog.safaribooksonline.com/2013/07/23/using-neo4j-from-python/
また、Neo4jの関連プロジェクトで、可視化をツールがあるようなので、それを使ってモデルを見ながら探索してみたいと思います。
という感じの小プロジェクトです。グラフデータベースは以前のパイソンハッカソンで使っている方がいて知ったのですが、SNSのような人間関係に始まり、点と線で表せるネットワーク上のデータを入れるために最適化されたデータベースです。これを使った可視化ツールがまた素晴らしくかっこ良くて、こんなツールとか見ると非常にドキドキするわけです。これはオープンソースのGephiというツール。
今回のミニプロジェクトでは、数時間という短い時間でしたが、日本語の単語(特に名詞)と単語の関係からどのようなネットワークが現れるのかを可視化することにチャレンジしました。その手段としては、AIALが研究用に収集したニュース記事を形態素解析し、頻度分析することで生成した結果を利用しました。こんなデータです
{“date_published”: “2013 09/16 00:21″, “length”: 2314, “contents_id”: 1192453750800140829, “word_count”: {“2566″: 2, “1287″: 2, “906″: 6, “1041″: 2, “1046″: 2, “667″: 2, “294″: 4, “3003″: 3, “1344″: 3, “1985″: 2, “3651″: 4, “5069″: 3, “4950″: 2, “6495″: 2, “482″: 2, “105″: 2, “5738″: 2, “2542″: 3, “1136″: 3, “369″: 2, “758″: 2, “890″: 2, “17275″: 2, “11004″: 2, “34266879″: 2}}
{“date_published”: “2013 09/16 00:21″, “length”: 2578, “contents_id”: 1192453742100140329, “word_count”: {“2566″: 2, “1287″: 2, “906″: 6, “1041″: 4, “3651″: 4, “1046″: 2, “1177″: 2, “667″: 3, “1947″: 3, “294″: 4, “7595″: 2, “3003″: 3, “1344″: 3, “1985″: 2, “108611″: 2, “2889″: 2, “5069″: 3, “4950″: 2, “6495″: 2, “482″: 2, “5604″: 2, “105″: 2, “5738″: 2, “2542″: 3, “1136″: 3, “369″: 2, “758″: 2, “890″: 2, “17275″: 2, “11004″: 2, “34266879″: 2}}
{“date_published”: “2013 09/16 00:21″, “length”: 2183, “contents_id”: 1192453750400140629, “word_count”: {“2566″: 2, “1287″: 2, “906″: 6, “1041″: 2, “1046″: 2, “667″: 2, “294″: 4, “3003″: 3, “1344″: 3, “1985″: 2, “3651″: 4, “5069″: 3, “4950″: 2, “6495″: 2, “482″: 2, “105″: 2, “5738″: 2, “2542″: 3, “1136″: 3, “369″: 2, “758″: 2, “890″: 2, “17275″: 2, “11004″: 2, “34266879″: 2}}
{“date_published”: “2013 09/16 00:21″, “length”: 2278, “contents_id”: 1192453741700140129, “word_count”: {“2566″: 2, “1287″: 2, “906″: 6, “1041″: 2, “1046″: 2, “667″: 2, “294″: 4, “3003″: 3, “1344″: 3, “1985″: 2, “3651″: 4, “5069″: 3, “4950″: 2, “6495″: 2, “482″: 2, “105″: 2, “5738″: 2, “2542″: 3, “1136″: 3, “369″: 2, “758″: 2, “890″: 2, “17275″: 2, “11004″: 2, “34266879″: 2}}
{“date_published”: “2013 09/16 00:21″, “length”: 2302, “contents_id”: 1192453751300140929, “word_count”: {“2566″: 2, “1287″: 2, “906″: 6, “1041″: 2, “1046″: 2, “667″: 2, “294″: 4, “3003″: 3, “1344″: 3, “1985″: 2, “3651″: 4, “5069″: 3, “4950″: 2, “6495″: 2, “482″: 2, “105″: 2, “5738″: 2, “2542″: 3, “1136″: 3, “369″: 2, “758″: 2, “890″: 2, “17275″: 2, “11004″: 2, “34266879″: 2}}
……..
上記は今回このイベントでパイソンデビューした白ヤギコーポレーション伊藤さんのコードです。パイソンからこれを行うためにPy2NeoというパイソンAPIを使いました。これをつかて数百記事を分析して出来たものをグラフで見てみると、こんなものが現れました。
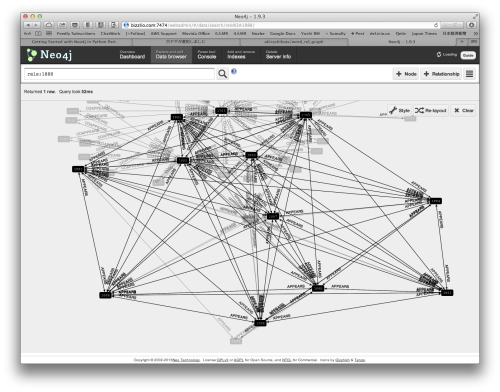
ビリビリします。こういうのがデフォルトのツールで簡単に出来てしまうのが、Neo4jの素晴らしいところなのです。一方で、一度でも一緒に出た単語は、回数にかかわらずつながって見えてしまうので、現在のグラフはすべての単語がすべての単語とつながったように見えています(特に近しい単語しか出ていないこともありますが)。ちなみに上記は「五輪」という単語と関連単語の関係なのですが、他の単語が何なのかすぐに確認する事ができないためこのままでは非常に示唆が小さいです。
また、今回の学びの一つとして、Neo2PyはHTMLを使ったREST経由でDBとやりとりしているため、それが大きなボトルネックになる、ということがわかりました。一つ一つのインサートコマンドを別コマンドとして動かしていたため、プロファイルを取ってみると、一番のボトルネックがurllib (パイソンのウェブコンテンツ取得ライブラリ)となっていました。バッチで処理することでこの問題はある程度解決されると思われますが、バッチで処理するためには処理全体の構成を変える必要があったりと色々面倒です。一方でNeo4jには”embedded”と呼ばれるパイソンAPIもあり、こちらはNeo4jの動くJVMクラスをパイソンから直接呼び出すためのJPypeという技術にもとづいているようで、高速化が見込めそうです。
最終的にはこれをBizzlioの実装として使うには速度の観点からイマイチ、という結論になり、この程度の分析であれば最近流行りのオンメモリKVSがいいだろうということになり帰ってからRedisを使って再実装しましたが、Redisについてはまた別の回にでも。もう少し時間があればグラフの可視化も含めもっともっと面白いことが出来たと思いますが、いずれにしても学びの多いハッカソンになりました。
【最後に】
AIALでは強い探究心をモットーにしており、ドキドキする研究テーマを最新技術で解決するプロジェクトを今後も引き続き仕掛けていきたいと思っています。現在AIALを擁する白ヤギコーポレーションでは絶賛仲間を募集中ですので、興味のある方はお気軽にご連絡の上、ランチでも行きましょう!
- 自然言語処理サイエンティスト: http://goo.gl/3Iei5k
- 「データを踊らせる」サーバー・インフラエンジニア:http://goo.gl/Z6Hrfj
